Python 开发表情包网站
「表情包」是一种利用图片来表示感情的方式。在各种社交软件的带动下,「表情包」已经形成了一种流行文化。互联网上,基本人人都会发表情;很多实时通讯软件中,「斗图」成为了一种活跃气氛的常见方式。不知你是否曾有过找不到表情包去应对别人的时候?
今天笔者分享用 Python 开发个人专属的表情包网站的方法,想用什么表情包搜一下就有了!
目标:获取海量表情包,存入数据库,然后搭建简单网站,通过输入关键字获取对应的的表情包。
创建数据库
首先,我们要从这个网站爬取表情包:斗图啦。
我们先来分析一下这个网页的源代码:
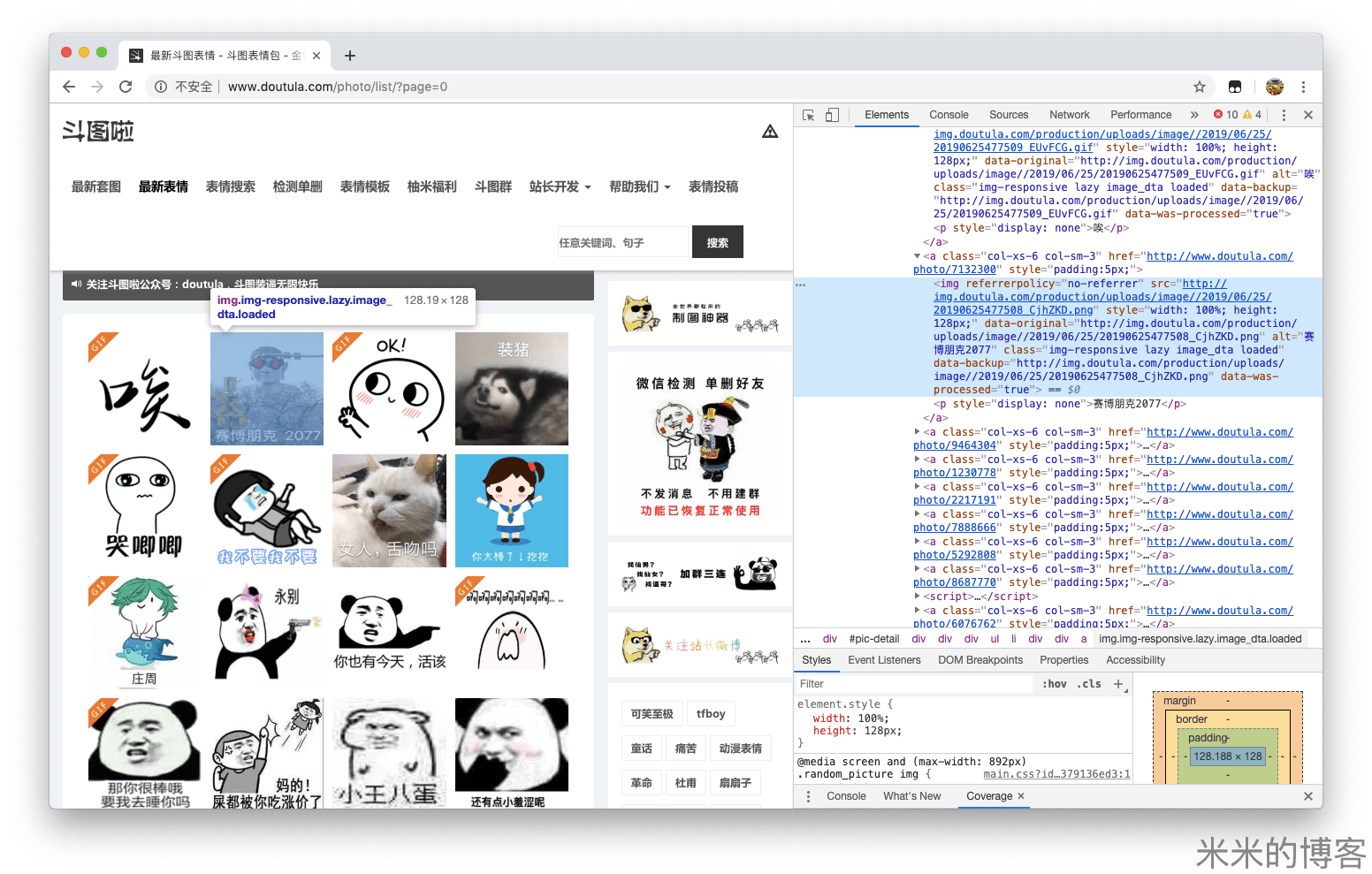
通过源码,我们可以发现需要获取的内容包括每个<img>标签的data-original和alt属性。通过爬虫获取网页,用正则表达式提取内容,然后存入数据库即可。
这里用到的数据库是 MySQL。如果还没有安装的话,不妨参考前面的文章 MySQL 8.0 的安装和使用。
安装完成后,你可以用 root,也可以创建一个新用户,来新建数据库和数据表,用来存放表情包:1
2
3
4
5
6
7
8
9
10#建立数据库images
CREATE DATABASE images;
USE images;
#然后在该数据库中新建一个表,并添加相应的name和imageUrl
CREATE TABLE images (
id int(10) UNSIGNED PRIMARY KEY NOT NULL AUTO_INCREMENT,
name varchar(1000),
imageUrl varchar(200)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
QUIT;
至此数据库方面的工作就完成了。
安装依赖
依赖包是requests,mysql-connector-python和Flask。使用pip进行安装即可。
获取海量表情包
创建 Python 文件,并用 Python 3 执行(记得将密码换成你自己的):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41#!/usr/bin/env python3
import requests
import re
import mysql.connector
# 连接数据库
conn = mysql.connector.connect(
host = "127.0.0.1", # 主机,一般没有服务器就填本机吧
port = 3306, # 端口,MySQL数据库的默认端口就是3306
database = "images", # 数据库名,与之前创建的相同
user = "username", # 用户名,如果是创建的用户需要在MySQL中授权
passwd = "password", # 密码,换成你的
charset = "utf8"
)
# 创建cursor
cursor = conn.cursor()
cursor.execute("SET NAMES utf8mb4")
# 获取图片列表
def getImagesList(page):
# 获取斗图网源代码
html = requests.get("http://www.doutula.com/photo/list/?page={}".format(page), headers = { "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0" }).text
# 正则表达式 通配符 .*? 匹配所有 () 分组匹配
reg = r'data-original="(.*?)".*?alt="(.*?)"'
# 增加匹配效率的 S 多行匹配
reg = re.compile(reg, re.S)
imagesList = re.findall(reg, html) # 获取name和imageUrl
for i in imagesList:
image_url = i[0]
image_title = i[1]
# %s 字符串格式化 防止注入
cursor.execute("insert into images values(null,%s,%s)", (image_title, image_url))
print("正在保存 {}".format(image_title))
conn.commit()
# 截至目前,网站共有1600多页,如果未来有更新,可以手动改下面range的范围
for i in range(0, 1650):
print("第{}页".format(i))
getImagesList(i)
cursor.close()
conn.close() # 不要忘记了关闭数据库连接
搭建网站前端
然后就是网站方面了,写一个简单的网站,实现输入关键字得到对应的图片。上代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39#!/usr/bin/env python3
from flask import Flask
from flask import render_template
from flask import request
import mysql.connector
app = Flask(__name__)
# 装饰器
# route 路由
def index():
return render_template("index.html")
def search():
# 接收用户关键字
keyword = request.args.get("kw")
count = request.args.get("count")
# 这里是一个模糊匹配,就是匹配和你输入的关键字类似的name,总共count条数据
cursor.execute("select name, imageURL from images where name like %s limit %s", ("%" + keyword + "%", int(count)))
data = cursor.fetchall()
# render_template模板能返回一个网页,而网页得存在新创建的templates文件夹里面才可以
return render_template("index.html", images = data)
# 程序的入口
if __name__ == "__main__":
conn = pymysql.connect(
host = "127.0.0.1",
port = 3306,
database = "images",
user = "username", # 将用户名换成你的
passwd = "password", # 将密码换成你的
charset = "utf8"
)
# 创建cursor
cursor = conn.cursor()
# 调试模式
# port 端口号 默认5000
app.run(debug = True, port = 5000, host = "0.0.0.0")
# index.html {{}}是放变量 {%%}是放方法
这里的host = "0.0.0.0"意味着程序将监听所有的流量,而不只是本机。
将这个文件命名为index.py。在这个 py 文件的同一目录下,新建文件夹,命名为templates,在该文件夹内创建index.html:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<html>
<head>
<meta charset="UTF-8">
<title>斗图网站</title>
</head>
<body>
<form action="/search">
关键字:<input type="text" name="kw">
<br>
查询的数量:<input type="text" name="count" value="100">
<br>
<input type="submit" value="查询">
</form>
{% for name, imageURL in images %}
<img src="{{ imageUrl }}" alt="{{ name }}">
{% endfor %}
</body>
</html>
完成后,回到上一目录,在命令行执行python3 index.py,然后访问localhost:5000即可开始斗图了!
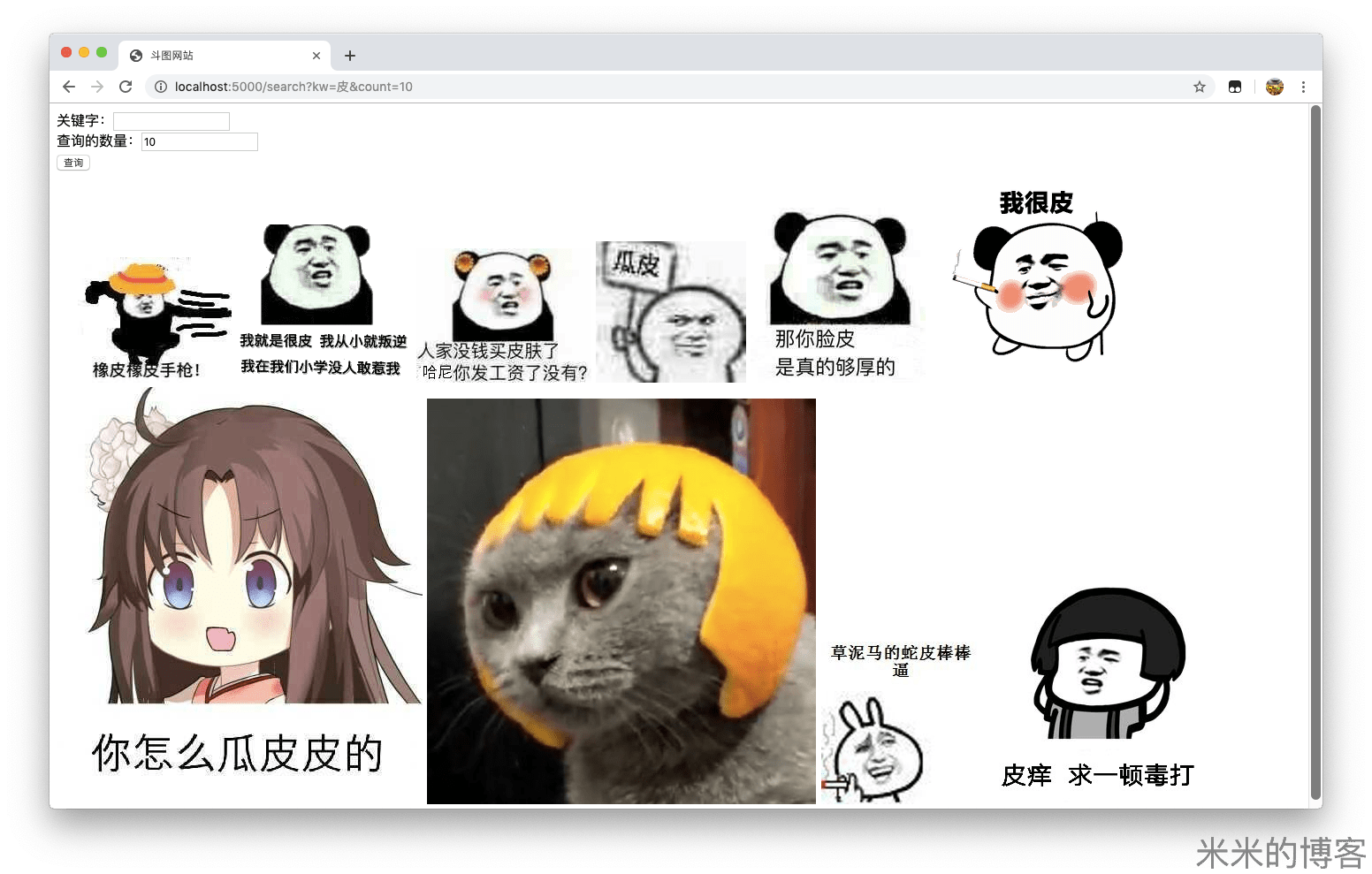
其他设备获取本机 IP 后,通过 5000 端口也可以正常浏览。
参考文章:
关于 Python 爬虫之获取海量表情包 + 存入数据库 + 搭建网站通过关键字查询表情包
Python 开发个人专属表情包网站,表情在手,天下我有