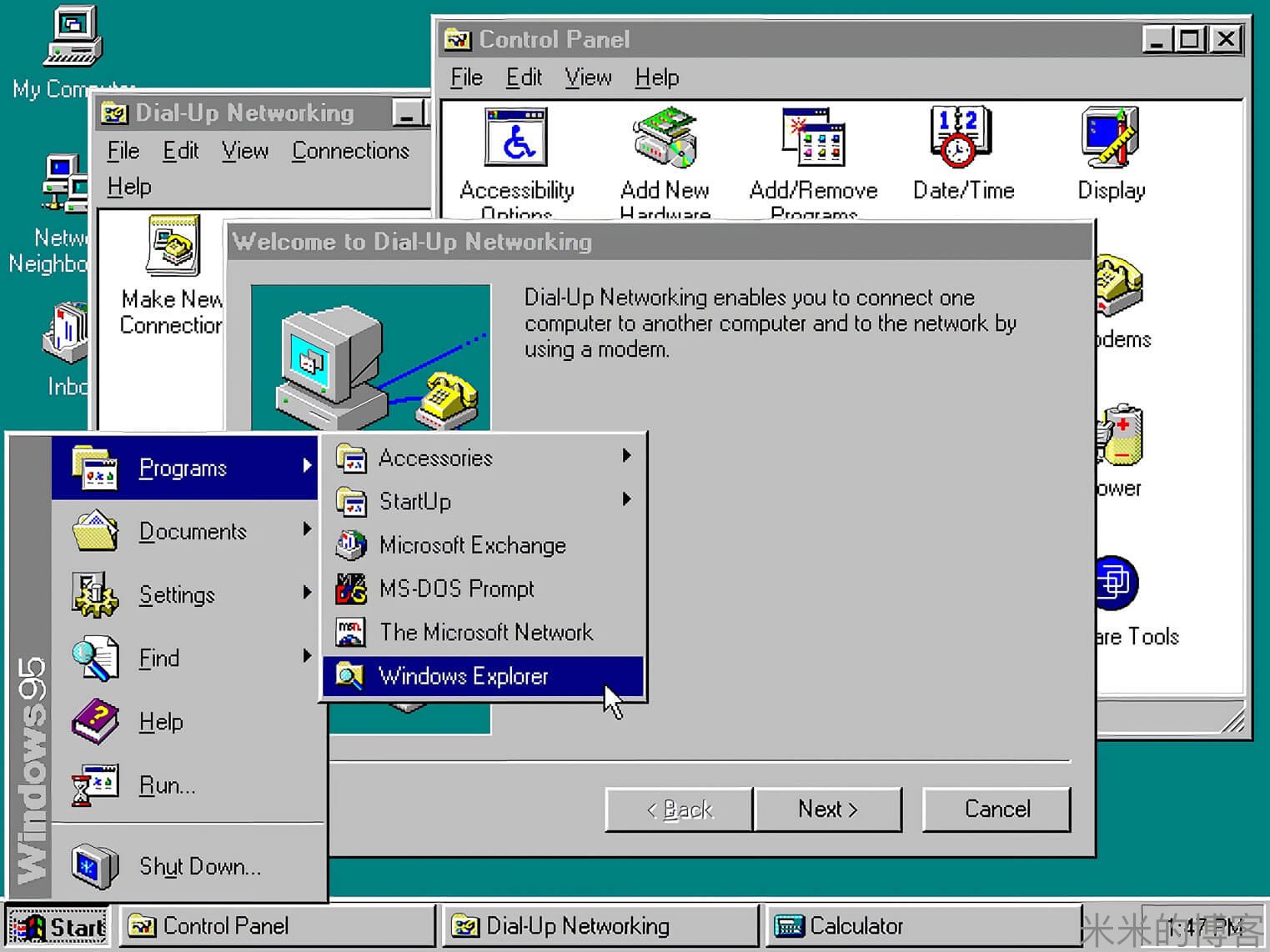
在 Win 95 中晃动鼠标竟能加速系统
Through the looking glass: Adding new hardware or overclocking what you've already got are among the leading ways to squeeze more performance out of your PC but in the earlier days of computing, all one had to do to give their PC a jolt was wiggle the mouse cursor around during an install.
添加新硬件或超频现有硬件是使 PC 获得更佳性能的主要方法。但在个人计算机的早期阶段,用户竟然还可以通过一个巧妙的办法来提升性能 —— 不停地晃动鼠标的光标。
I'm a self-professed fidgeter, especially at the computer. It's not uncommon to catch me moving the mouse all around with zero intent, even if I'm busy reading a story or watching a video.
我自认为是一个手抖的人,尤其是在电脑前。即使我在忙着用电脑读故事或看视频,你也会发现我在毫无目的地移动鼠标。
I chalk it up to the earlier days of computing when keeping the mouse active seemed to have a tangible benefit on system performance. Turns out, it wasn't just in our imagination.
我把它归结为在上古时期,保持鼠标活动似乎对系统性能有明显的好处。事实证明,这并不只是我们的想象。
According to a running thread over on Stack Exchange, moving the mouse cursor in Windows 95 did indeed speed up performance due to a flaw in the way the OS generates events and the fact that many applications are event driven.
根据 Stack Exchange 上一个正在热烈讨论的主题,在 Windows 95 中移动鼠标光标确实提升了性能,因为操作系统的事件生成方法存在缺陷,并且许多应用程序都是基于事件来驱动的。
As one user explains:
正如一位用户解释到:
Windows 95 applications often use asynchronous I/O, that is they ask for some file operation like a copy to be performed and then tell the OS that they can be put to sleep until that operation finishes. By sleeping they allow other applications to run, rather than wasting CPU time endlessly asking if the file operation has completed yet.
Windows 95 应用程序通常采用了异步 I/O,也就是说,在它们要求执行某些文件操作的时候(例如要执行的副本),会向操作系统表示其能够在操作完成之前转入休眠状态。通过这项休眠机制,其它应用程序将可以穿插空档来运行,而不是无休止地询问文件操作是否已经完成,从而浪费 CPU 时间。
For reasons that are not entirely clear, but probably due to performance problems on low end machines, Windows 95 tends to bundle up the messages about I/O completion and doesn't immediately wake up the application to service them. However, it does wake the application for user input, presumably to keep it feeling responsive, and when the application is awake it will handle any pending I/O messages too.
目前原因尚不完全清楚,但一个猜测是,这可能是为了解决低端计算机上的性能问题 ——Windows 95 倾向于捆绑关于 I/O 完成的消息,并且不会立即唤醒应用程序来为它们提供服务。不过,在用户输入时,操作系统会唤醒应用程序,这可能是为了让应用程序保持响应;而当应用程序处于唤醒状态时,它就能够处理任何挂起的 I/O 消息。
Thus wiggling the mouse causes the application to process I/O messages faster, and install quicker. The effect was quite pronounced; large applications that could take an hour to install could be reduced to 15 minutes with suitable mouse input.
换言之,晃动鼠标可以使应用程序更快地处理 I/O 消息,并加快安装速度。效果相当明显:配合合适的鼠标输入,原先可能需要一个小时安装的大型应用程序,耗时可以减少到 15 分钟。
As a youth, I'd keep my mouse cursor active as much as possible -- and especially during installs -- simply because I didn't want the screensaver to trigger and bog down system resources. Sure, I could have just set the timeout to longer on the screensaver, but that's beside the point. As it turns out, my actions were actually helpful, and not for the reason I thought.
在我年轻的时候,我尽可能地让鼠标光标处于活动状态 —— 尤其是在安装期间 —— 只是因为我不想让屏幕保护程序触发并阻塞系统资源。当然,我可以把屏保上的超时设置得更长一些,但这不是重点。事实证明,我的行为实际上是有帮助的 —— 即使这并不是我的初衷。
本文翻译自:Wiggling the mouse in Windows 95 made the operating system faster